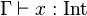SEE THE VIDEO AT
Network topology

Network topology is the arrangement of the various elements (links, nodes, etc.) of a computer network.[1][2] Essentially, it is the topological[3] structure of a network and may be depicted physically or logically. Physical topology is the placement of the various components of a network, including device location and cable installation, whilelogical topology illustrates how data flows within a network, regardless of its physical design. Distances between nodes, physical interconnections, transmission rates, or signal types may differ between two networks, yet their topologies may be identical.
An example is a local area network (LAN): Any given node in the LAN has one or more physical links to other devices in the network; graphically mapping these links results in a geometric shape that can be used to describe the physical topology of the network. Conversely, mapping the data flow between the components determines the logical topology of the network.
Topology[edit]
There are two basic categories of network topologies:[4] physical topologies and logical topologies.
The cabling layout used to link devices is the physical topology of the network. This refers to the layout of cabling, the locations of nodes, and the interconnections between the nodes and the cabling.[1] The physical topology of a network is determined by the capabilities of the network access devices and media, the level of control or fault tolerance desired, and the cost associated with cabling or telecommunications circuits.
The logical topology in contrast, is the way that the signals act on the network media, or the way that the data passes through the network from one device to the next without regard to the physical interconnection of the devices. A network’s logical topology is not necessarily the same as its physical topology. For example, the originaltwisted pair Ethernet using repeater hubs was a logical bus topology with a physical star topology layout. Token Ring is a logical ring topology, but is wired as a physical star from the Media Access Unit.
The logical classification of network topologies generally follows the same classifications as those in the physical classifications of network topologies but describes the path that the data takes between nodes being used as opposed to the actual physical connections between nodes. The logical topologies are generally determined by network protocols as opposed to being determined by the physical layout of cables, wires, and network devices or by the flow of the electrical signals, although in many cases the paths that the electrical signals take between nodes may closely match the logical flow of data, hence the convention of using the terms logical topology andsignal topology interchangeably.
Logical topologies are often closely associated with Media Access Control methods and protocols. Logical topologies are able to be dynamically reconfigured by special types of equipment such as routers and switches.

Diagram of different network topologies.
The study of network topology recognizes eight basic topologies:[5] point-to-point, bus, star, ring or circular, mesh, tree, hybrid, or daisy chain.
Point-to-point[edit]
The simplest topology with a dedicated link between two endpoints. Switched point-to-point topologies are the basic model of conventional telephony. The value of a permanent point-to-point network is unimpeded communications between the two endpoints. The value of an on-demand point-to-point connection is proportional to the number of potential pairs of subscribers and has been expressed as Metcalfe’s Law.
- Permanent (dedicated)
- Easiest to understand, of the variations of point-to-point topology, is a point-to-point communications channel that appears, to the user, to be permanently associated with the two endpoints. A children’s tin can telephone is one example of a physical dedicated channel.
-
- Within many switched telecommunications systems, it is possible to establish a permanent circuit. One example might be a telephone in the lobby of a public building, which is programmed to ring only the number of a telephone dispatcher. “Nailing down” a switched connection saves the cost of running a physical circuit between the two points. The resources in such a connection can be released when no longer needed, for example, a television circuit from a parade route back to the studio.
- Switched:
- Using circuit-switching or packet-switching technologies, a point-to-point circuit can be set up dynamically and dropped when no longer needed. This is the basic mode of conventional telephony.
Bus[edit]

Bus network topology
- In local area networks where bus topology is used, each node is connected to a single cable, by the help of interface connectors.This central cable is the backbone of the network and is known as the bus (thus the name). A signal from the source travels in both directions to all machines connected on the bus cable until it finds the intended recipient. If the machine address does not match the intended address for the data, the machine ignores the data. Alternatively, if the data matches the machine address, the data is accepted. Because the bus topology consists of only one wire, it is rather inexpensive to implement when compared to other topologies. However, the low cost of implementing the technology is offset by the high cost of managing the network. Additionally, because only one cable is utilized, it can be the single point of failure.
- Linear bus
-
- The type of network topology in which all of the nodes of the network are connected to a common transmission medium which has exactly two endpoints (this is the ‘bus’, which is also commonly referred to as the backbone, or trunk) – all data that is transmitted between nodes in the network is transmitted over this common transmission medium and is able to be received by all nodes in the network simultaneously.[1]
-
- Note: When the electrical signal reaches the end of the bus, the signal is reflected back down the line, causing unwanted interference. As a solution, the two endpoints of the bus are normally terminated with a device called a terminator that prevents this reflection.
- Distributed bus
-
- The type of network topology in which all of the nodes of the network are connected to a common transmission medium which has more than two endpoints that are created by adding branches to the main section of the transmission medium – the physical distributed bus topology functions in exactly the same fashion as the physical linear bus topology (i.e., all nodes share a common transmission medium).
Star[edit]

Star network topology
- In local area networks with a star topology, each network host is connected to a central hub with a point-to-point connection. So it can be said that every computer is indirectly connected to every other node with the help of the hub. In Star topology every node (computer workstation or any other peripheral) is connected to a central node called hub, router or switch. The switch is the server and the peripherals are the clients. The network does not necessarily have to resemble a star to be classified as a star network, but all of the nodes on the network must be connected to one central device. All traffic that traverses the network passes through the central hub. The hub acts as a signal repeater. The star topology is considered the easiest topology to design and implement. An advantage of the star topology is the simplicity of adding additional nodes. The primary disadvantage of the star topology is that the hub represents a single point of failure.
- Extended star
- A type of network topology in which a network that is based upon the physical star topology has one or more repeaters between the central node and the peripheral or ‘spoke’ nodes, the repeaters being used to extend the maximum transmission distance of the point-to-point links between the central node and the peripheral nodes beyond that which is supported by the transmitter power of the central node or beyond that which is supported by the standard upon which the physical layer of the physical star network is based.
-
- If the repeaters in a network that is based upon the physical extended star topology are replaced with hubs or switches, then a hybrid network topology is created that is referred to as a physical hierarchical star topology, although some texts make no distinction between the two topologies.
- Distributed Star
- A type of network topology that is composed of individual networks that are based upon the physical star topology connected in a linear fashion – i.e., ‘daisy-chained’ – with no central or top level connection point (e.g., two or more ‘stacked’ hubs, along with their associated star connected nodes or ‘spokes’).
Ring[edit]

Ring network topology
- A network topology is set up in a circular fashion in such a way that they make a closed loop. This way data travels around the ring in one direction and each device on the ring acts as a repeater to keep the signal strong as it travels. Each device incorporates a receiver for the incoming signal and a transmitter to send the data on to the next device in the ring. The network is dependent on the ability of the signal to travel around the ring. When a device sends data, it must travel through each device on the ring until it reaches its destination. Every node is a critical link.[4] In a ring topology, there is no server computer present; all nodes work as a server and repeat the signal. The disadvantage of this topology is that if one node stops working, the entire network is affected or stops working.
Mesh[edit]
The value of fully meshed networks is proportional to the exponent of the number of subscribers, assuming that communicating groups of any two endpoints, up to and including all the endpoints, is approximated by Reed’s Law.
- Fully connected network

Fully connected mesh topology
-
- A fully connected network is a communication network in which each of the nodes is connected to each other. In graph theory it known as a complete graph. A fully connected network doesn’t need to use switching or broadcasting. However, its major disadvantage is that the number of connections grows quadratically with the number of nodes, as per the formula
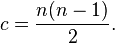
-
- and so it is extremely impractical for large networks. A two-node network is technically a fully connected network.
- Partially connected

Partially connected mesh topology
-
- The type of network topology in which some of the nodes of the network are connected to more than one other node in the network with a point-to-point link – this makes it possible to take advantage of some of the redundancy that is provided by a physical fully connected mesh topology without the expense and complexity required for a connection between every node in the network.
Tree[edit]
| This section may be confusing or unclear to readers. (June 2011) |
A tree topology is essentially a combination of bus topology and star topology. The nodes of bus topology are replaced with standalone star topology networks. This results in both disadvantages of bus topology and advantages of star topology.
For example, if the connection between two groups of networks is broken down due to breaking of the connection on the central linear core, then those two groups cannot communicate, much like nodes of a bus topology. However, the star topology nodes will effectively communicate with each other.
It has a root node, intermediate nodes, and ultimate nodes. This structure is arranged in a hierarchical form and any intermediate node can have any number of the child nodes.
But the tree topology is practically impossible to construct, because the node in the network is nothing, but the computing device can have maximum one or two connections, so we cannot attach more than 2 child nodes to the computing device (or parent node).[citation needed] There are many sub structures under tree topology, but the most convenient is B-tree topology whereby finding errors is relatively easy.[citation needed]
Many supercomputers use a fat tree network,[6] including the Yellowstone (supercomputer), the Tianhe-2, the Meiko Scientific CS-2, the Earth Simulator, the Cray X2, the CM-5, and many Altix supercomputers.
- A network that is based upon the physical hierarchical topology must have at least three levels in the hierarchy of the tree, since a network with a central ‘root’ node and only one hierarchical level below it would exhibit the physical topology of a star.
- A network that is based upon the physical hierarchical topology and with a branching factor of 1 would be classified as a physical linear topology.
- The branching factor, f, is independent of the total number of nodes in the network and, therefore, if the nodes in the network require ports for connection to other nodes the total number of ports per node may be kept low even though the total number of nodes is large; – this makes the effect of the cost of adding ports to each node totally dependent upon the branching factor and may therefore be kept as low as required without any effect upon the total number of nodes that are possible.
- The total number of point-to-point links in a network that is based upon the physical hierarchical topology will be one less than the total number of nodes in the network.
- If the nodes in a network that is based upon the physical hierarchical topology are required to perform any processing upon the data that is transmitted between nodes in the network, the nodes that are at higher levels in the hierarchy will be required to perform more processing operations on behalf of other nodes than the nodes that are lower in the hierarchy. Such a type of network topology is very useful and highly recommended.
- Advantages
-
- It is scalable. Secondary nodes allow more devices to be connected to a central node.
- Point to point connection of devices.
- Having different levels of the network makes it more manageable hence easier fault identification and isolation.
-
-
- An example of this network could be cable TV technology. Other examples are in dynamic tree based wireless networks for military, mining and otherwise mobile applications.
- Disadvantages
-
- Maintenance of the network may be an issue when the network spans a great area.
- Since it is a variation of bus topology, if the backbone fails, the entire network is crippled.
-
-
- An example of this network could be cable TV technology. Other examples are in dynamic tree based wireless networks for military, mining and otherwise mobile applications.[7] The Naval Postgraduate School, Monterey CA, demonstrated such tree based wireless networks for border security.[8] In a pilot system, aerial cameras kept aloft by balloons relayed real time high resolution video to ground personnel via a dynamic self healing tree based network.
Hybrid[edit]
Hybrid networks use a combination of any two or more topologies, in such a way that the resulting network does not exhibit one of the standard topologies (e.g., bus, star, ring, etc.). For example, a tree network connected to a tree network is still a tree network topology. A hybrid topology is always produced when two different basic network topologies are connected. Two common examples for Hybrid network are: star ring network and star bus network
- A star ring network consists of two or more ring topologies connected using a multistation access unit (MAU) as a centralized hub.
- A Star Bus network consists of two or more star topologies connected using a bus trunk (the bus trunk serves as the network’s backbone).
While grid and torus networks have found popularity in high-performance computing applications, some systems have used genetic algorithms to design custom networks that have the fewest possible hops in between different nodes. Some of the resulting layouts are nearly incomprehensible, although they function quite well.[citation needed]
A Snowflake topology is really a “Star of Stars” network, so it exhibits characteristics of a hybrid network topology but is not composed of two different basic network topologies being connected.
Daisy chain[edit]
Except for star-based networks, the easiest way to add more computers into a network is by daisy-chaining, or connecting each computer in series to the next. If a message is intended for a computer partway down the line, each system bounces it along in sequence until it reaches the destination. A daisy-chained network can take two basic forms: linear and ring.
- A linear topology puts a two-way link between one computer and the next. However, this was expensive in the early days of computing, since each computer (except for the ones at each end) required two receivers and two transmitters.
- By connecting the computers at each end, a ring topology can be formed. An advantage of the ring is that the number of transmitters and receivers can be cut in half, since a message will eventually loop all of the way around. When a node sends a message, the message is processed by each computer in the ring. If the ring breaks at a particular link then the transmission can be sent via the reverse path thereby ensuring that all nodes are always connected in the case of a single failure.
Centralization[edit]
The star topology reduces the probability of a network failure by connecting all of the peripheral nodes (computers, etc.) to a central node. When the physical star topology is applied to a logical bus network such asEthernet, this central node (traditionally a hub) rebroadcasts all transmissions received from any peripheral node to all peripheral nodes on the network, sometimes including the originating node. All peripheral nodes may thus communicate with all others by transmitting to, and receiving from, the central node only. The failure of a transmission line linking any peripheral node to the central node will result in the isolation of that peripheral node from all others, but the remaining peripheral nodes will be unaffected. However, the disadvantage is that the failure of the central node will cause the failure of all of the peripheral nodes.
If the central node is passive, the originating node must be able to tolerate the reception of an echo of its own transmission, delayed by the two-way round trip transmission time (i.e. to and from the central node) plus any delay generated in the central node. An active star network has an active central node that usually has the means to prevent echo-related problems.
A tree topology (a.k.a. hierarchical topology) can be viewed as a collection of star networks arranged in a hierarchy. This tree has individual peripheral nodes (e.g. leaves) which are required to transmit to and receive from one other node only and are not required to act as repeaters or regenerators. Unlike the star network, the functionality of the central node may be distributed.
As in the conventional star network, individual nodes may thus still be isolated from the network by a single-point failure of a transmission path to the node. If a link connecting a leaf fails, that leaf is isolated; if a connection to a non-leaf node fails, an entire section of the network becomes isolated from the rest.
To alleviate the amount of network traffic that comes from broadcasting all signals to all nodes, more advanced central nodes were developed that are able to keep track of the identities of the nodes that are connected to the network. These network switches will “learn” the layout of the network by “listening” on each port during normal data transmission, examining the data packets and recording the address/identifier of each connected node and which port it is connected to in a lookup table held in memory. This lookup table then allows future transmissions to be forwarded to the intended destination only.
Decentralization[edit]
In a mesh topology (i.e., a partially connected mesh topology), there are at least two nodes with two or more paths between them to provide redundant paths to be used in case the link providing one of the paths fails. This decentralization is often used to compensate for the single-point-failure disadvantage that is present when using a single device as a central node (e.g., in star and tree networks). A special kind of mesh, limiting the number of hops between two nodes, is a hypercube. The number of arbitrary forks in mesh networks makes them more difficult to design and implement, but their decentralized nature makes them very useful. In 2012 the IEEE published the Shortest path bridging protocol to ease configuration tasks and allows all paths to be active which increases bandwidth and redundancy between all devices.[9][10][11][12][13]
This is similar in some ways to a grid network, where a linear or ring topology is used to connect systems in multiple directions. A multidimensional ring has a toroidal topology, for instance.
A fully connected network, complete topology, or full mesh topology is a network topology in which there is a direct link between all pairs of nodes. In a fully connected network with n nodes, there are n(n-1)/2 direct links. Networks designed with this topology are usually very expensive to set up, but provide a high degree of reliability due to the multiple paths for data that are provided by the large number of redundant links between nodes. This topology is mostly seen in military applications.